
Previously:
v5.7
Linux v5.8 was released in August, 2020. Here s my summary of various security things that caught my attention:
arm64 Branch Target Identification
Dave Martin
added support for ARMv8.5 s Branch Target Instructions (
BTI), which are enabled in
userspace at execve() time, and all the time
in the kernel (which required manually marking up a lot of non-C code, like assembly and
JIT code).
With this in place, Jump-Oriented Programming (JOP, where code gadgets are chained together with jumps and calls) is no longer available to the attacker. An attacker s code must make direct function calls. This basically reduces the usable code available to an attacker from every word in the kernel text to only function entries (or jump targets). This is a low granularity forward-edge Control Flow Integrity (CFI) feature, which is important (since it greatly reduces the potential targets that can be used in an attack) and cheap (implemented in hardware). It s a good first step to strong CFI, but (as we ve seen with things like CFG) it isn t usually strong enough to stop a motivated attacker. High granularity CFI (which uses a more specific branch-target characteristic, like function prototypes, to track expected call sites) is not yet a hardware supported feature, but the software version will be coming in the future by way of
Clang s CFI implementation.
arm64 Shadow Call Stack
Sami Tolvanen landed the
kernel implementation of Clang s Shadow Call Stack (
SCS), which protects the kernel against Return-Oriented Programming (ROP) attacks (where code gadgets are chained together with returns). This backward-edge CFI protection is implemented by keeping a second dedicated stack pointer register (
x18) and keeping a copy of the return addresses stored in a separate shadow stack . In this way, manipulating the regular stack s return addresses will have no effect. (And since a copy of the return address continues to live in the regular stack, no changes are needed for back trace dumps, etc.)
It s worth noting that unlike BTI (which is hardware based), this is a software defense that relies on the location of the Shadow Stack (i.e. the value of
x18) staying secret, since the memory could be written to directly. Intel s hardware ROP defense (CET) uses a hardware shadow stack that isn t directly writable. ARM s hardware defense against ROP is
PAC (which is actually designed as an arbitrary CFI defense it can be used for forward-edge too), but that depends on having ARMv8.3 hardware. The expectation is that SCS will be used until PAC is available.
Kernel Concurrency Sanitizer infrastructure added
Marco Elver landed support for the
Kernel Concurrency Sanitizer, which is a new debugging infrastructure to find data races in the kernel, via
CONFIG_KCSAN. This immediately found real bugs, with some fixes having
already landed too. For more details, see the
KCSAN documentation.
new capabilities
Alexey Budankov
added CAP_PERFMON, which is designed to allow access to
perf(). The idea is that this capability gives a process access to only read aspects of the running kernel and system. No longer will access be needed through the much more powerful abilities of
CAP_SYS_ADMIN, which has many ways to change kernel internals. This allows for a split between controls over the confidentiality (read access via CAP_PERFMON) of the kernel vs control over integrity (write access via CAP_SYS_ADMIN).
Alexei Starovoitov
added CAP_BPF, which is designed to separate BPF access from the all-powerful
CAP_SYS_ADMIN. It is designed to be used in combination with
CAP_PERFMON for tracing-like activities and
CAP_NET_ADMIN for networking-related activities. For things that could change kernel integrity (i.e. write access),
CAP_SYS_ADMIN is still required.
network random number generator improvements
Willy Tarreau made the
network code s random number generator less predictable. This will further frustrate any attacker s attempts to recover the state of the RNG externally, which might lead to the ability to hijack network sessions (by correctly guessing packet states).
fix various kernel address exposures to non-
CAP_SYSLOG
I fixed several situations where kernel addresses were still being exposed to unprivileged (i.e. non-
CAP_SYSLOG) users, though usually only through odd corner cases. After
refactoring how capabilities were being checked for files in
/sys and
/proc, the
kernel modules sections,
kprobes, and
BPF exposures got fixed. (Though in doing so, I briefly made things much worse before getting it
properly fixed. Yikes!)
RISCV W^X detection
Following up on his recent work to
enable strict kernel memory protections on RISCV, Zong Li has now added
support for CONFIG_DEBUG_WX as seen for other architectures. Any writable and executable memory regions in the kernel (which are lovely targets for attackers) will be loudly noted at boot so they can get corrected.
execve() refactoring continues
Eric W. Biederman continued working on
execve() refactoring, including getting rid of the
frequently problematic recursion used to locate binary handlers. I used the opportunity to dust off some old
binfmt_script regression tests and get them into the kernel selftests.
multiple
/proc instances
Alexey Gladkov modernized
/proc internals and provided a way to have
multiple /proc instances mounted in the same PID namespace. This allows for having multiple views of
/proc, with different features enabled. (Including the newly added
hidepid=4 and
subset=pid mount
options.)
set_fs() removal continues
Christoph Hellwig, with Eric W. Biederman, Arnd Bergmann, and others, have been diligently working to entirely remove the kernel s
set_fs() interface, which has long been a source of security flaws due to weird confusions about which address space the kernel thought it should be accessing. Beyond things like the lower-level per-architecture
signal handling code, this has needed to touch various
parts of the
ELF loader, and
networking code too.
READ_IMPLIES_EXEC is no more for native 64-bit
The
READ_IMPLIES_EXEC flag was a work-around for dealing with the addition of non-executable (NX) memory when x86_64 was introduced. It was designed as a way to mark a memory region as well, since we don t know if this memory region was expected to be executable, we must assume that if we need to read it, we need to be allowed to execute it too . It was designed mostly for stack memory (where trampoline code might live), but it would carry over into all
mmap() allocations, which would mean sometimes exposing a large attack surface to an attacker looking to find executable memory. While normally this didn t cause problems on modern systems that correctly marked their ELF sections as NX, there were still some awkward corner-cases. I fixed this by splitting
READ_IMPLIES_EXEC from the ELF
PT_GNU_STACK marking on
x86 and
arm/arm64, and declaring that a native 64-bit process would never gain
READ_IMPLIES_EXEC on
x86_64 and
arm64, which matches the behavior of other native 64-bit architectures that correctly didn t ever implement
READ_IMPLIES_EXEC in the first place.
array index bounds checking continues
As part of the ongoing work to use modern flexible arrays in the kernel, Gustavo A. R. Silva added the
flex_array_size() helper (as a cousin to
struct_size()). The
zero/one-member into flex array conversions continue with over a hundred commits as we slowly get closer to being able to build with
-Warray-bounds.
scnprintf() replacement continues
Chen Zhou joined Takashi Iwai in
continuing to replace potentially unsafe uses of
sprintf() with
scnprintf(). Fixing all of these will make sure the kernel avoids nasty buffer concatenation surprises.
That s it for now! Let me know if there is anything else you think I should mention here. Next up: Linux v5.9.
2021, Kees Cook. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 License.

 A bug-fix release of the
A bug-fix release of the 
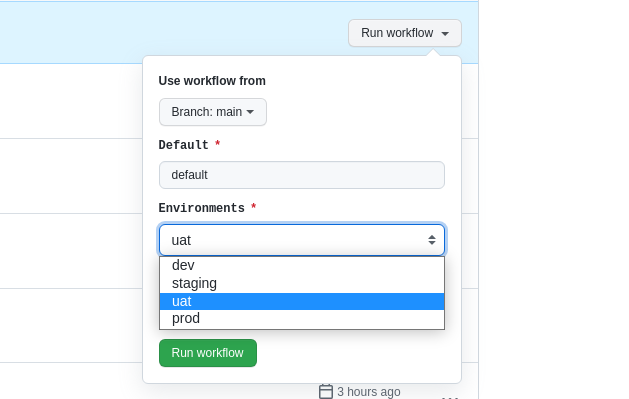
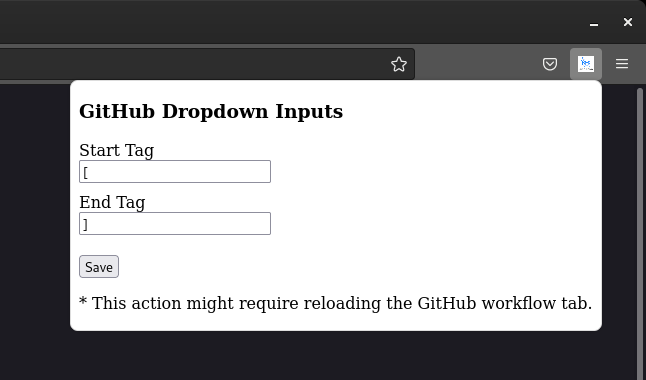
 So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using
So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using 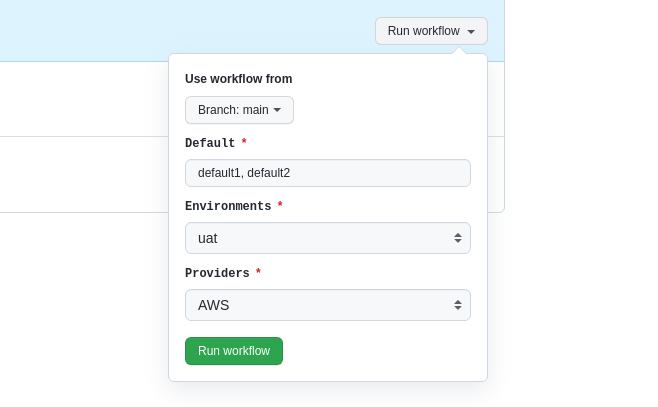
 So, 2021 isn't bad enough yet, but don't despair, people are working to fix that:
So, 2021 isn't bad enough yet, but don't despair, people are working to fix that:
 A new release of the
A new release of the  When I started my Master's degree in January 2018, I was confident I would be
done in a year and half. After all, I only had one year of classes and I
figured 6 months to write a thesis would be plenty.
Three years later, I'm finally done: the final version of my thesis was
accepted on January 22nd 2021.
My thesis, entitled What are the incentive structures of Free Software? An
economic analysis of Free Software's specific development model, can be
When I started my Master's degree in January 2018, I was confident I would be
done in a year and half. After all, I only had one year of classes and I
figured 6 months to write a thesis would be plenty.
Three years later, I'm finally done: the final version of my thesis was
accepted on January 22nd 2021.
My thesis, entitled What are the incentive structures of Free Software? An
economic analysis of Free Software's specific development model, can be 
 Fifteen years have passed since I started my career in IT which is quite some time. I've been playing with computers for 25 years now, which makes me quite knowledgeable about the field, for sure.However, while I was fully prepared to bargain with computers, I was not prepared to do so with humans. The whole career management thing was unknown to me. I had no useful skills to navigate within the enterprise organization. I had to learn the ropes the hard way, failing along the way. It hurt.Almost ten years ago, I had the chance to meet a new colleague Alexis Monville. Alexis was a team facilitator, and I started to work with him on many non-technical levels. He taught me a lot about agility and team organization. Working on this set of new skills changed how I envisioned my work and how I fit into the company.
Fifteen years have passed since I started my career in IT which is quite some time. I've been playing with computers for 25 years now, which makes me quite knowledgeable about the field, for sure.However, while I was fully prepared to bargain with computers, I was not prepared to do so with humans. The whole career management thing was unknown to me. I had no useful skills to navigate within the enterprise organization. I had to learn the ropes the hard way, failing along the way. It hurt.Almost ten years ago, I had the chance to meet a new colleague Alexis Monville. Alexis was a team facilitator, and I started to work with him on many non-technical levels. He taught me a lot about agility and team organization. Working on this set of new skills changed how I envisioned my work and how I fit into the company. Alexis Monville
Alexis Monville The book!
The book!